


Sponsored Links
TOP > Techniques > Y-Wing
Solving Techniques 6
Y-Wing
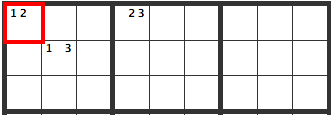
This is a Y-wing. There is a [12] in the upper left cell, highlighted in red.

If a 1 goes here, the [13] on the lower right cell becomes a [3]. The X’s indicate the where the 3 can’t go.

If there is a [2] in this cell, the [23] to its right becomes a [3]. The X’s indicate the where the 3 can’t go.
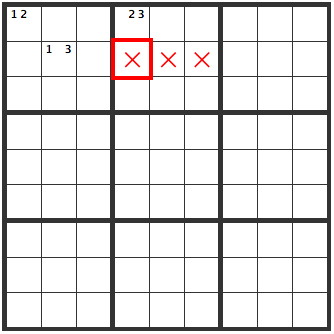
In the overlapping areas, [R2C4], [R2C5] and [R2C6], a [3] can’t be entered (the cells with X’s), hence a 3 can be eliminated as a candidate number.
Sponsored Links
Other Y-wing patterns
The pattern below is also an XY-wing.
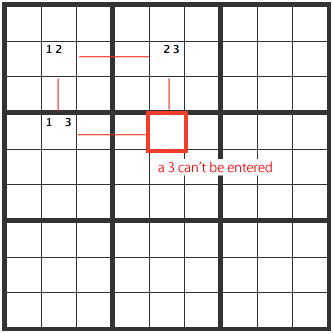
There are two numbers in the cells serving as starting points. Look for the cells with two numbers in them, that will be affected by the first set of cells. Finally, look for where these two cells intersect.
It seems like this would occur often, but the cells that meet the criteria are not that common. So unless you make a conscious effort to use this technique, it can happen that you solve the problem using a different method.
This technique is worth remembering, since it can be useful when trying to solve the puzzle quickly.
Names of cells in Sudoku
| R1C1 | R1C2 | R1C3 | R1C4 | R1C5 | R1C6 | R1C7 | R1C8 | R1C9 |
| R2C1 | R2C2 | R2C3 | R2C4 | R2C5 | R2C6 | R2C7 | R2C8 | R2C9 |
| R3C1 | R3C2 | R3C3 | R3C4 | R3C5 | R3C6 | R3C7 | R3C8 | R3C9 |
| R4C1 | R4C2 | R4C3 | R4C4 | R4C5 | R4C6 | R4C7 | R4C8 | R4C9 |
| R5C1 | R5C2 | R5C3 | R5C4 | R5C5 | R5C6 | R5C7 | R5C8 | R5C9 |
| R6C1 | R6C2 | R6C3 | R6C4 | R6C5 | R6C6 | R6C7 | R6C8 | R6C9 |
| R7C1 | R7C2 | R7C3 | R7C4 | R7C5 | R7C6 | R7C7 | R7C8 | R7C9 |
| R8C1 | R8C2 | R8C3 | R8C4 | R8C5 | R8C6 | R8C7 | R8C8 | R8C9 |
| R9C1 | R9C2 | R9C3 | R9C4 | R9C5 | R9C6 | R9C7 | R9C8 | R9C9 |
Sponsored Links
